|
人工智能的普适应用面临着三大问题,一是数据。数据是人工智能最重要的资源,人工智能需要海量的有效数据集以训练出更好的模型,但在数据隐私和数据监管的前提之下,需要解决数据的使用权和安全使用等问题。 二是训练成本。人工智能模型的规模以每年 10 倍的速度增长,需要超大算力进行计算,导致人工智能总训练成本持续攀升。三是集中化。大多数人工智能研究由少数科技巨头控制,其他组织面临着人工智能人才和技术的缺乏问题,而与此同时,人工智能的开发者缺乏方法变现他们的成果,只能将技术卖给科技巨头。 PlatON 2.0 白皮书呈现的,是借助于区块链和隐私计算技术,建立一个基础设施网络,在这个网络上,开发人员可以低成本获得包括数据和算力在内的资源,训练人工智能模型并作为人工智能服务发布到网络,该服务同时能与其他人工智能服务或代理交互、组合,而任何人或组织都可以从这个网络获得人工智能算法或服务。随着该基础设施网络的发展,将孕育出一个繁荣的去中心化的人工智能市场,人们可以在该网络上交易与人工智能相关的「商品」,比如数据、算力、人工智能算法、人工智能服务。 如果更进一步,这个自组织的分散式协作网络将可能成为一个总体大于其各部分之和的生态体,连接人工智能并使其相互协作学习,最终涌现通用人工智能。 PlatON 分三个阶段来实现上述目标:
计算的基本要素是数据、算法和算⼒,隐私计算⽹络将数据、算法和算⼒紧密结合起来,构建一个完整的计算⽣态。 在隐私计算网络中,数据节点和计算节点通过 P2P 协议连接到系统中,发布数据和算⼒,这些数据⼀般保存在本地。利用数据和算力,通过安全多⽅计算、联邦学习等技术对算法进⾏协同计算,数据可⽤不可⻅,不仅数据的隐私得到保护,计算结果如训练完成的人工智能模型的隐私也能得到保护。 PlatON 的隐私计算⽹络技术架构如下图所示: 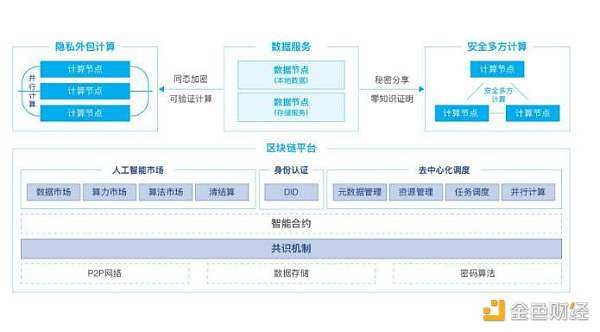 (责任编辑:admin)
(责任编辑:admin) |