|
「缓存」的作用是保留由于「批」值不足或距离节点地址太远而不受「储备」保护的块。当容量达到限度,缓存就会被定期修剪,最长时间未被请求的块将被删除。块的受欢迎程度可以通过最后一次收到请求的时间来预测,更多 SWAP 收入的块将优先得到保留。与投机缓存相结合,这种垃圾收集(garbage collecting)策略使运营者从带宽激励中获得的利润最大化,而在网络层面上,实现了受欢迎内容的自动扩展。
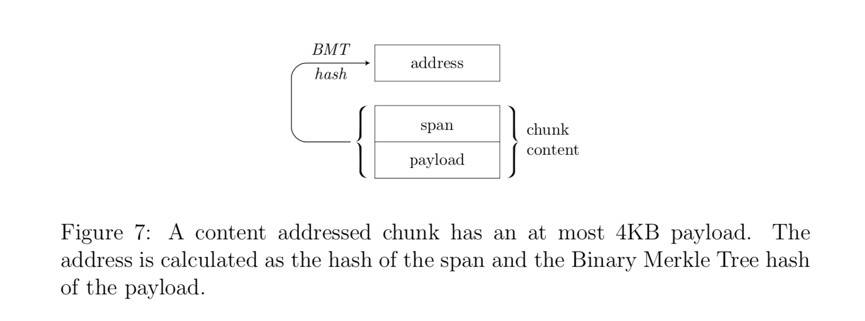
块类型在上面我们将块定义为 DISC 中数据的标准单位。Swarm 中存在两种基本的块类型:内容寻址块(content-addressed chunks)和单一所有者块(single-owner chunks)。 内容寻址块的地址基于其数据的哈希摘要(hash digest)。使用哈希作为块的地址可以验证块数据的完整性。Swarm 在块数据的小部分上使用基于默克尔树(Merkle tree)的 BMT (Binary Merkle Tree)哈希算法。
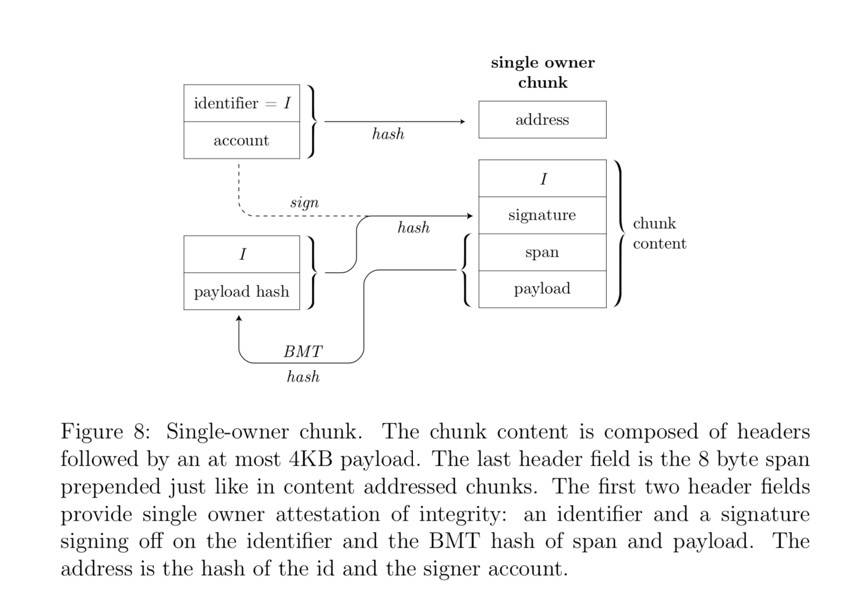
单一所有者块的地址通过所有者地址和一个 identifier 进行哈希计算而得。单一所有者块数据的完整性由所有者的加密签名来保证,该签名证明任意块的数据与 identifier 之间的关联。换句话说,每个 identity 都拥有 Swarm 地址空间的一部分,他们可以在其中自由地将内容分配给一个地址。
Swarm API 的功能除了块,Swarm 还公开了用于应对实现更高等级概念的 API,例如文件、具有各种元数据的文件的分层集合,甚至是 inter-node 消息传递等。这些 API 试图镜像那些已经在 web 上使用的 API。更新颖的构想和数据结构可以绘制在这些更高的层级之上,从而为希望从 DISC 提供的隐私和去中心化的核心产品中获益的所有人带来丰富多样的可能性。 文件和集合大于单个块中允许的 4 千字节的数据会被拆分为多个块。一组同属的块由一个 Swarm 哈希树(hash-tree)表示,该哈希树对文件在上传过程中分割成块的方式进行编码。这棵树由一组叶节点块(leaf node chunks)组成,包含数据本身,由一层或几层中间块引用,每个中间块包含对其子块的引用。 然后,整个文件的内容地址由根块的哈希摘要确定,即横跨整个文件的哈希树的默克尔根(Merkle root)。这样,文件的地址就变成了它的校验和(checksum),从而可以验证内容的完整性。将文件表示为块的平衡默克尔树,还提供了对文件的高效随机访问,结果上可以高效地进行范围查询。 (责任编辑:admin) |