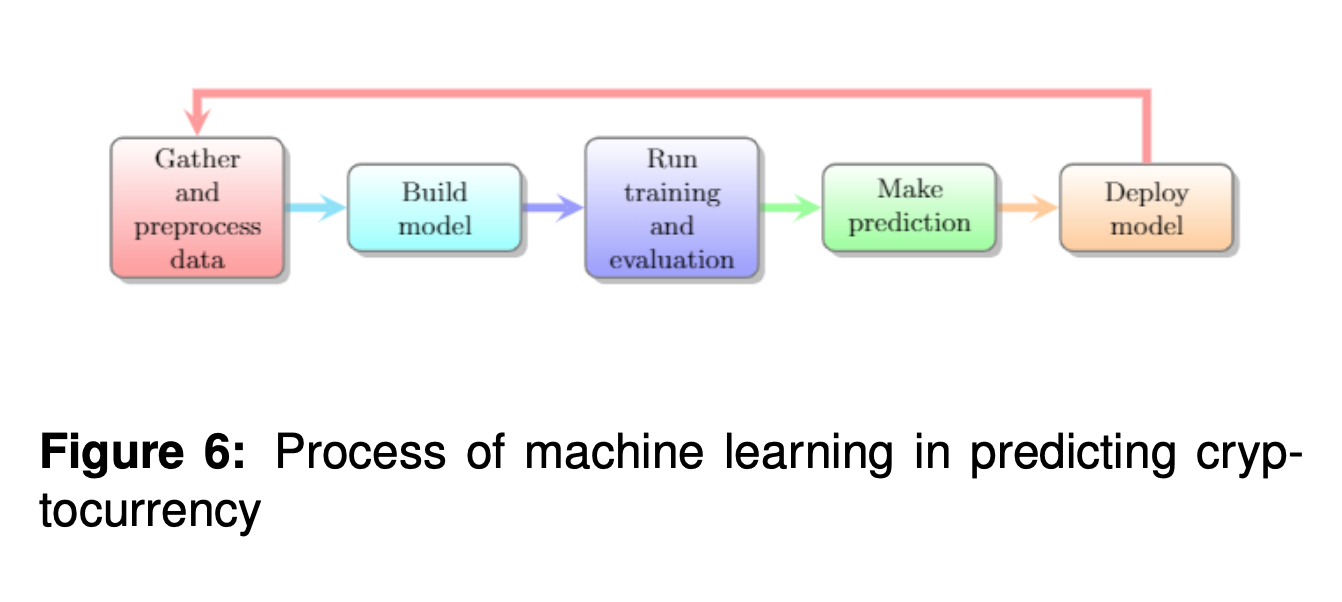
3.3. 新兴交易技术加密货币的新兴交易策略包括基于计量经济学和机器学习技术的策略。 3.3.1. 加密货币计量经济学 计量经济学方法运用统计和经济理论相结合的方法来估计经济变量并预测其价值[244]。统计模型使用数学方程对从数据中提取的信息进行编码[152]。在某些情况下,统计建模技术可以快速提供足够精确的模型[24]。也可以使用其他方法,例如基于情绪的预测和基于长期和短期波动分类的预测[64]。波动率的预测可以用来判断加密货币的价格波动,这对加密货币相关衍生品的定价也有价值[147]。 在使用计量经济学研究加密货币交易时,研究人员对时间序列数据应用统计模型,如广义自回归条件异方差(GARCH)和BEKK(以Baba、Engle、Kraft和Kroner的名字命名,1995[96])模型来评估加密货币的波动[55]。线性统计模型是一种评估价格与解释变量之间线性关系的方法[196]。当存在多个解释变量时,我们可以用多个线性模型来模拟解释变量(独立变量)和反应变量(因变量)之间的线性关系。时间序列分析中常用的线性统计模型是自回归滑动平均(ARMA)模型[69]。 3.3.2. 机器学习技术 机器学习是开发比特币和其他加密货币交易策略的有效工具[185],因为它可以推断人类通常无法直接观察到的数据关系。从最基本的角度来看,机器学习依赖于两个主要部分的定义:输入特征和目标函数。输入特征(数据源)的定义是基础和技术分析知识发挥作用的地方。我们可以将输入分为若干组特征,例如,基于经济指标(如国内生产总值指标、利率等)、社会指标(谷歌趋势、推特等)、技术指标(价格、成交量等)和其他季节性指标(时间、星期几等)的特征。目标函数定义了用于判断机器学习模型是否已经学习到当前任务的适应度准则。典型的预测模型试图预测数字(如价格)或分类(如趋势)看不见的结果。机器学习模型通过使用历史输入数据(有时称为样本)来训练,将其中的模式归纳为看不见(样本外)的数据,以(近似)实现目标函数定义的目标。显然,就交易而言,我们的目标是从市场指标中推断出交易信号,这些指标有助于预测资产未来的回报。 泛化误差是机器学习在实际应用中普遍存在的问题,在金融应用中具有极其重要的意义。在我们实际使用模型进行预测之前,我们需要使用统计方法(如交叉验证)来验证模型。在机器学习中,这通常被称为“验证”。使用机器学习技术预测加密货币的过程如图6所示。
根据主学习循环的形式,我们可以将机器学习方法分为三类:有监督学习、无监督学习和强化学习。有监督学习用于从有标记的训练数据中导出预测函数。带标签的训练数据意味着每个训练实例都包含输入和预期输出。通常,这些预期输出是由主管生成的,代表模型的预期行为。交易中使用最多的标签来自于样本中的未来资产回报。无监督学习试图从未标记的训练数据中推断结构,它可以用于探索性数据分析中发现隐藏的模式或根据任何预定义的相似性度量对数据进行分组。强化学习利用经过训练的软件代理来最大化效用函数,该函数定义了他们的目标;这足够灵活,允许代理用短期回报来交换未来的回报。在金融部门,一些交易挑战可以表示为一种博弈,在这种博弈中,代理人的目标是在期末实现收益最大化。 (责任编辑:admin) |