键值数据库区块链本质上是个数据库,和比较为大众熟悉关系型数据库不同,以太坊使用的键值(K-V)类型数据库,其底层基于 Google 的 Level DB,适用于写多读少的场景。关系型数据库历经多年发展,被程序员所接受,也非常利于普通人理解。关系型数据库的结构是一系列的表。 键值数据库是新发展出来的非关系型数据库,结构相对简单:键作为唯一的标识符,值存储数据,值可以是任何东西,不需要遵循表的结构,灵活多变且扩展性强。键值和关系数据库相比扩展性好,可以提供大数据量的读写,常被用于缓存。 区块链的数据根据状态和交易的抽象结构如下:
以太坊的区块数据包括区块头和区块体,区块头包含许多字段。从结构来看,以太坊的主干就是三棵树:状态树、交易树和收据树。 以太坊的主要字段是 State Root(状态树),包含了账户余额、声明、随机数等,状态树采用的是 Merkel-Patrica 结构,需要不断的更新。而交易树和收据树不需要更新,所以采用了 Merkel 的数据结构:交易数据是永久数据,永久数据已经记录不会被改变。状态树储存每个以太坊账户的地址余额,一经发生交易就会修改。
永久储存与临时储存如前所述,以太坊的底层数据是以 K-V 形式储存在底层 LevelDB 里的。但是 LevelDB 适合于写多读少的场景,所以真正用于读取、查询的数据库是 StateDb,它管理着所有账户的集合,账户的呈现形式是 stateObjectStateDB。其直接面向业务,是底层数据库(LevelDB)和业务模型的之间的存储模块。它采用两级缓存机制,以满足查询、更新、调用等功能。第一级缓存为 map 形式,存储 stateObject,二级缓存以 MPT 形式存储。当 stateObject 有变动的时候,实例化的 stateObject 会更新,当 IntermediateRoot() 被调用后,他们会被提交到 MPT 上,当 CommitTo() 被调用后,他们会被提交到底层 levelDB 中。这就形成了三级缓存结构。使用多存数据库的好处是,当需要回滚的时候,直接调用 stsateDB 中 MPT 树的根节点进行数据还原即可。 (责任编辑:admin) |

 来源:HyperLedger
来源:HyperLedger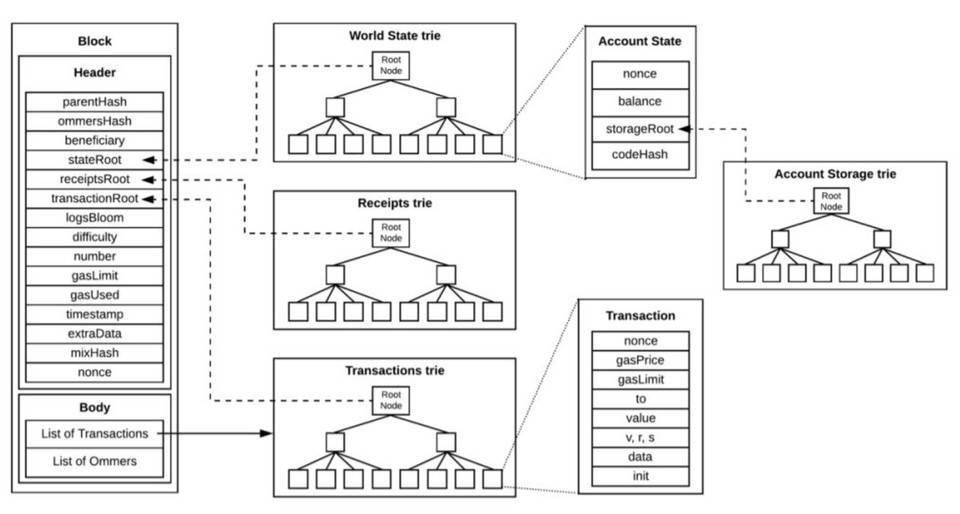 来源:Lucas Saldanha
来源:Lucas Saldanha