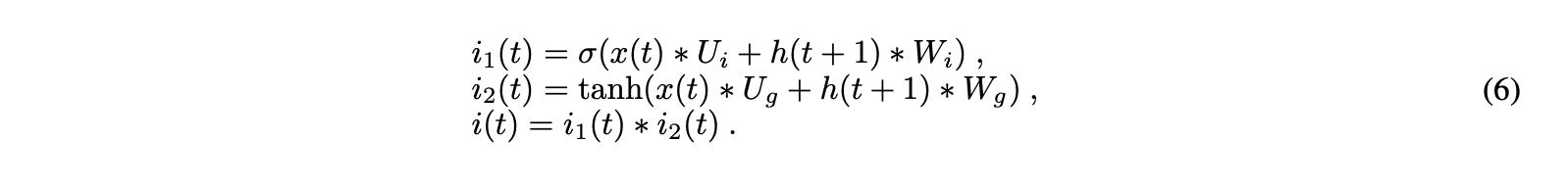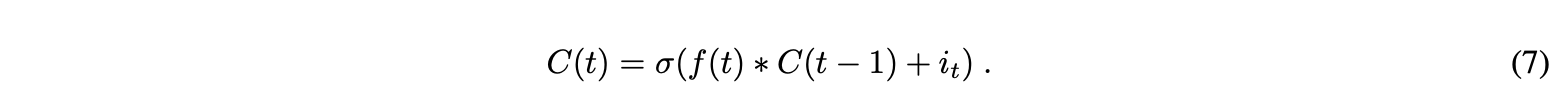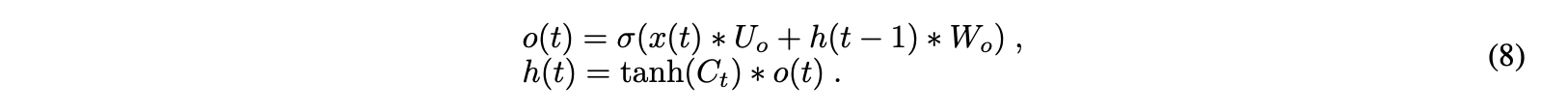|
第二个门是输入门。在这个阶段,单元状态被更新。先前的隐藏状态和当前输入最初表示为sigmoid激活函数的输入(值越接近1,输入越相关)。为了提高网络调谐,它还将隐藏状态和电流输入传递给tanh函数,以压缩−1和1之间的值。然后将tanh和sigmoid的输出逐元素相乘(在下面的公式中,符号*表示两个矩阵的逐元素相乘)。等式6中的sigmoid输出确定了要从tanh输出中保留的重要信息:
单元状态可以在输入门激活之后确定。接下来,将上一时间步的单元状态逐元素乘以遗忘门输出。这会导致在单元格状态下,当值与接近0的值相乘时,忽略值。输入门输出按元素添加到单元状态。方程7中的新单元状态是输出:
最后一个门是输出门,它指定下一个隐藏状态的值,该值包含一定量的先前输入信息。在这里,当前输入和先前的隐藏状态相加并转发到sigmoid函数。然后新的细胞状态被转移到tanh函数。最后,将tanh输出与sigmoid输出相乘,以确定隐藏状态可以携带哪些信息。输出是一个隐藏的新状态。新的单元状态和新的隐藏状态然后通过等式8移动到下一阶段:
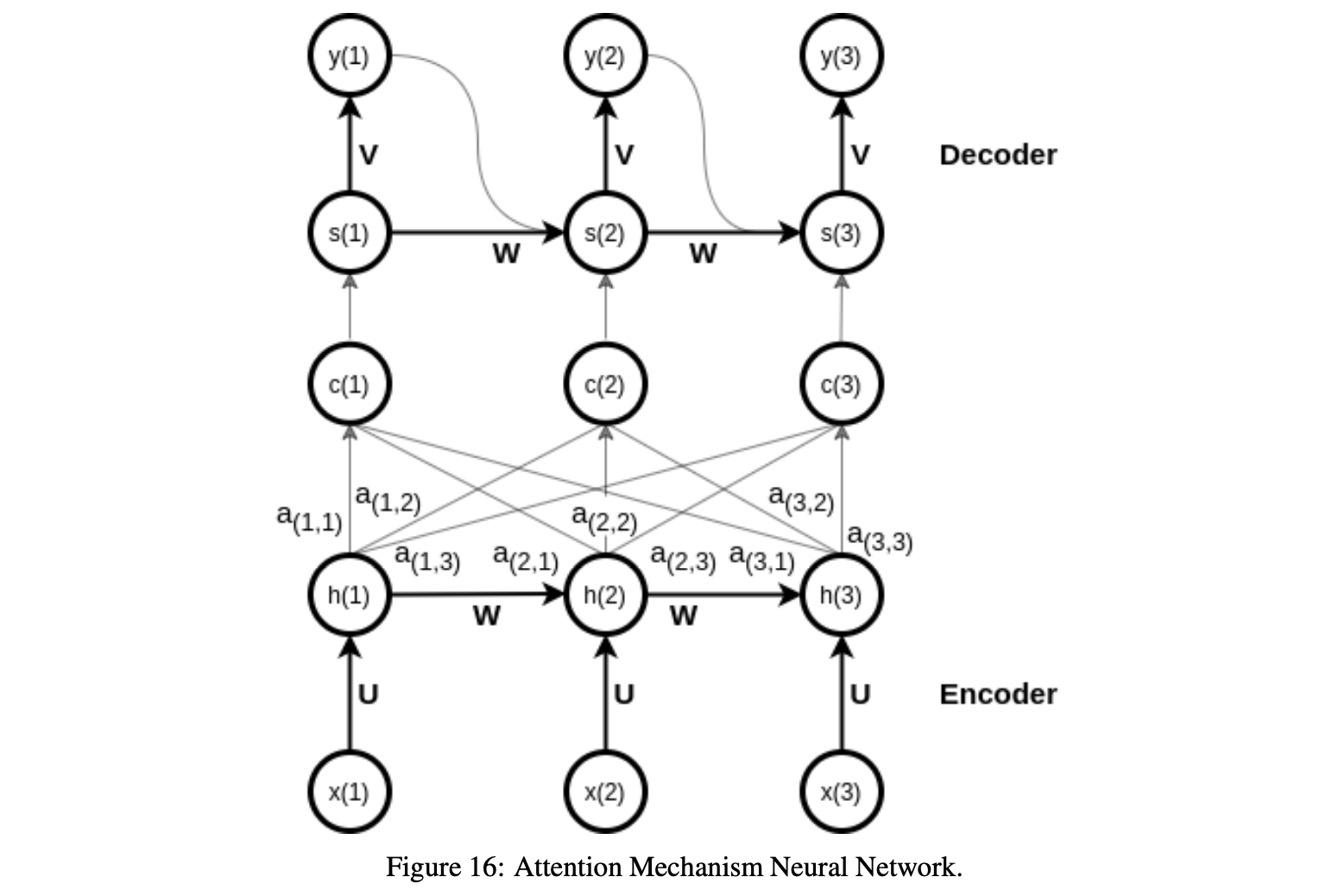
为了进行这一分析,我们使用Keras框架[7]进行深度学习。我们的模型由一个堆叠的LSTM层和一个密集连接的输出层和一个神经元组成。 3.3 注意机制神经网络 注意函数是深度学习算法的一个重要方面,它是编码器-译码器范式的扩展,旨在提高长输入序列的输出。图16显示了AMNN背后的关键思想,即允许解码器在解码期间有选择地访问编码器信息。这是通过为每个解码器步骤创建一个新的上下文向量来实现的,根据之前的隐藏状态以及所有编码器的隐藏状态来计算它,并为它们分配可训练的权重。通过这种方式,注意力技巧赋予输入序列不同的优先级,并更多地关注最重要的输入。
编码器操作与编码器-解码器混合操作本身非常相似。每个输入序列的表示在每个时间步确定,作为前一时间步的隐藏状态和当前输入的函数。 最终隐藏状态包括来自先前隐藏表示和先前输入的所有编码信息。 注意机制和编解码器模型之间的关键区别在于,对于每个解码器步骤t,计算一个新的背景向量c(t)。我们如下进行以测量时间步长t的上下文向量c(t)。首先,对于编码器的时间步长j和解码器的时间步长t的每个组合,使用等式(9)中的加权和来计算所谓的对齐分数e(j,t): (责任编辑:admin) |