|
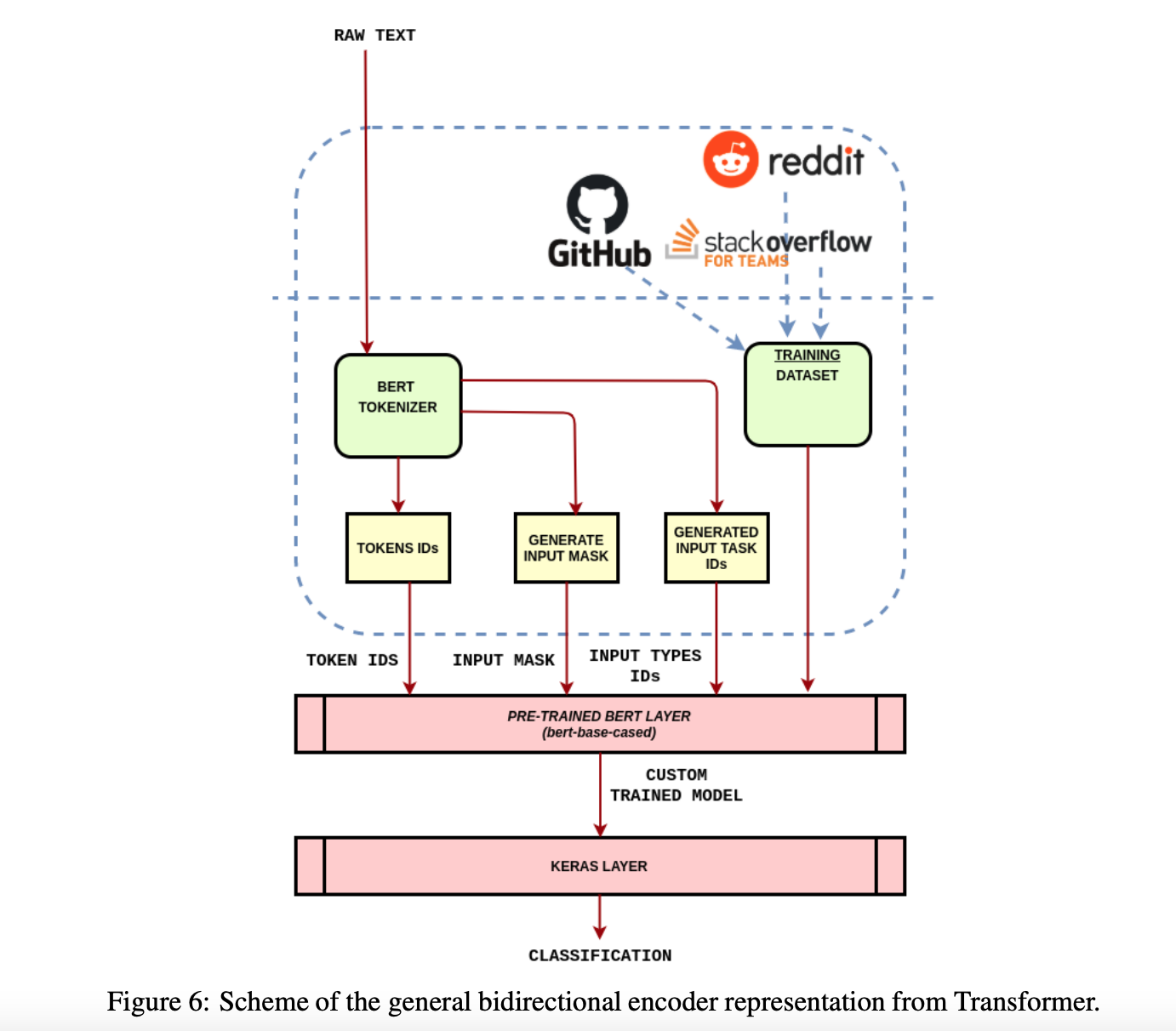
通过广泛的预训练模型学习的权重,可以在以后的特定任务中重用,只需根据特定的数据集调整权重即可。这将允许我们通过捕获特定数据集的较低层次的复杂性,利用预先训练的语言模型通过更精细的权重调整所学到的知识。 我们在Transformer包中使用Tensorflow和Keras Python库来利用这些预训练神经网络的功能。特别地,我们使用了BERT基案例预训练模型。图6显示了用于训练用于提取社交媒体指标的三个NN分类器的体系结构设计。此图显示了用于训练最终模型的三个gold数据集,即Github、Stack Overflow和Reddit。
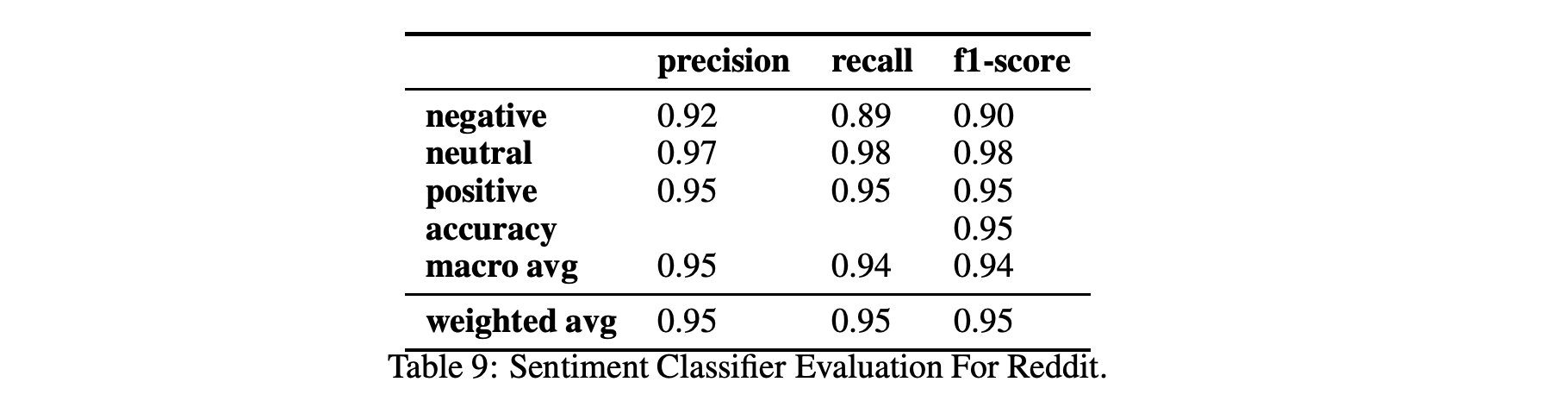
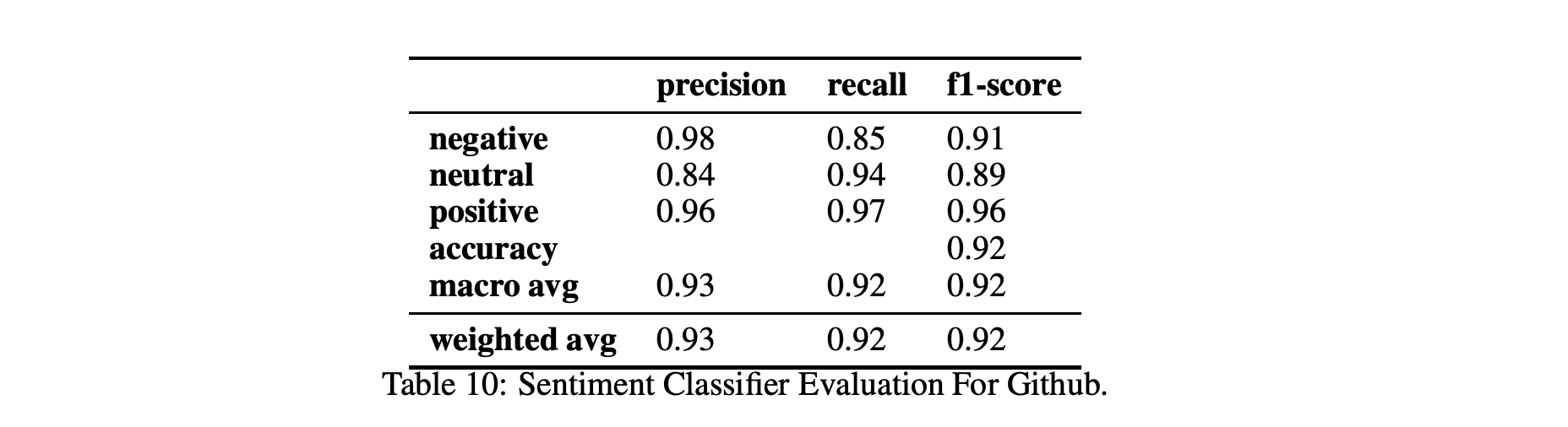
特别是,我们使用了一个情感标签数据集,该数据集由从Stackoverflow用户评论中挖掘出来的4,423条帖子组成,用于训练Github的情感模型:两个平台上的评论都是使用软件开发人员和工程师的技术术语编写的。我们还使用了来自Github的4,200个句子的情感标记数据集[23]。最后,我们使用了一个情感标签数据集,其中包含超过33K个标签Reddit用户的评论. 表9、10和11显示了情绪和情绪分类在两个不同数据集Github和Reddit上的性能。
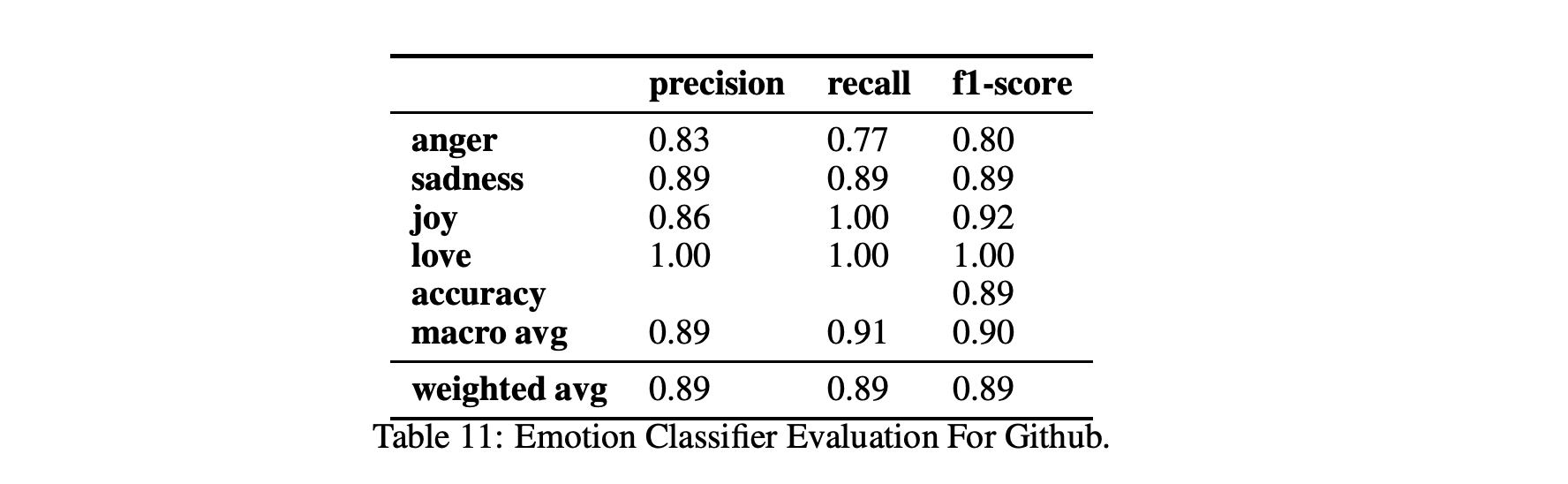
2.3.1 Github上的社交媒体指标 比特币和以太坊项目都是开源的,因此代码和贡献者之间的所有交互都可以在GitHub上公开获得[26]。积极的贡献者不断地打开、评论和关闭所谓的“问题/issue”。问题是开发过程的一个元素,它包含有关发现的bug的信息、关于代码中要实现的新功能的建议、新特性或正在开发的新功能。它是跟踪所有开发过程阶段的一种优雅而有效的方法,即使在涉及大量远程开发人员的复杂和大型项目中也是如此。一个问题可以被“评论”,这意味着开发人员可以围绕它展开子讨论。他们通常会对某一特定问题添加评论,以强调正在采取的行动或就可能的解决方案提出建议。发布在GitHub上的每个评论都有时间戳;因此,可以获得准确的时间和日期,并为本研究中考虑的每个影响度量生成一个时间序列。 对于情绪分析,我们使用2.3中解释的BERT分类器,该分类器使用由Ortu等人[24]开发并由Murgia等人[23]扩展的公共Github情感数据集进行训练。这个数据集特别适合我们的分析,因为情绪分析算法是根据从Apache软件基金会的Jira问题跟踪系统中提取的开发人员评论进行训练的,因此在Github和Reddit的软件工程领域和上下文中(考虑选定的子Reddit)。该分类器可以分析出爱、愤怒、喜悦和悲伤,F1得分接近0.89。 (责任编辑:admin) |