|
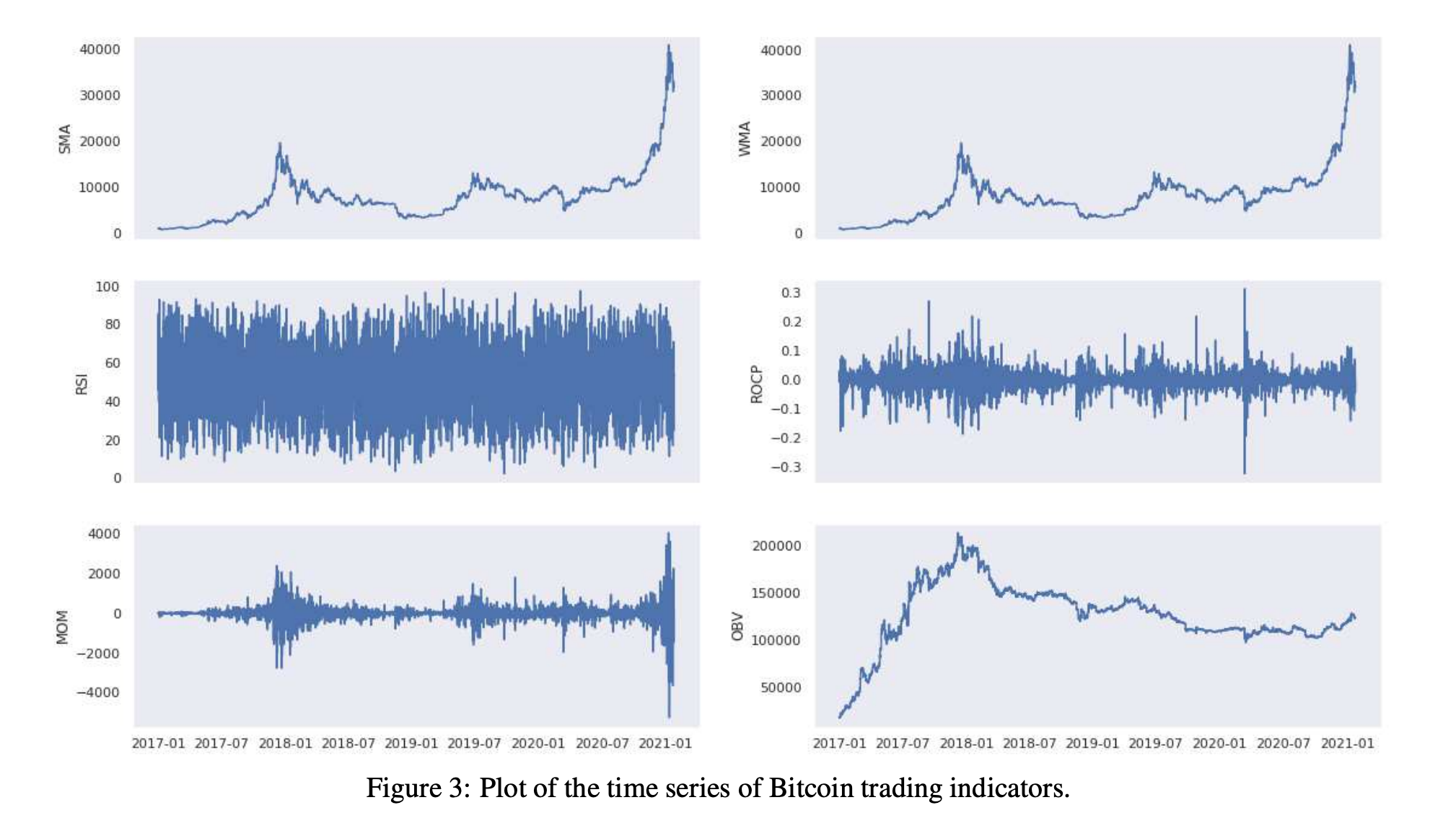
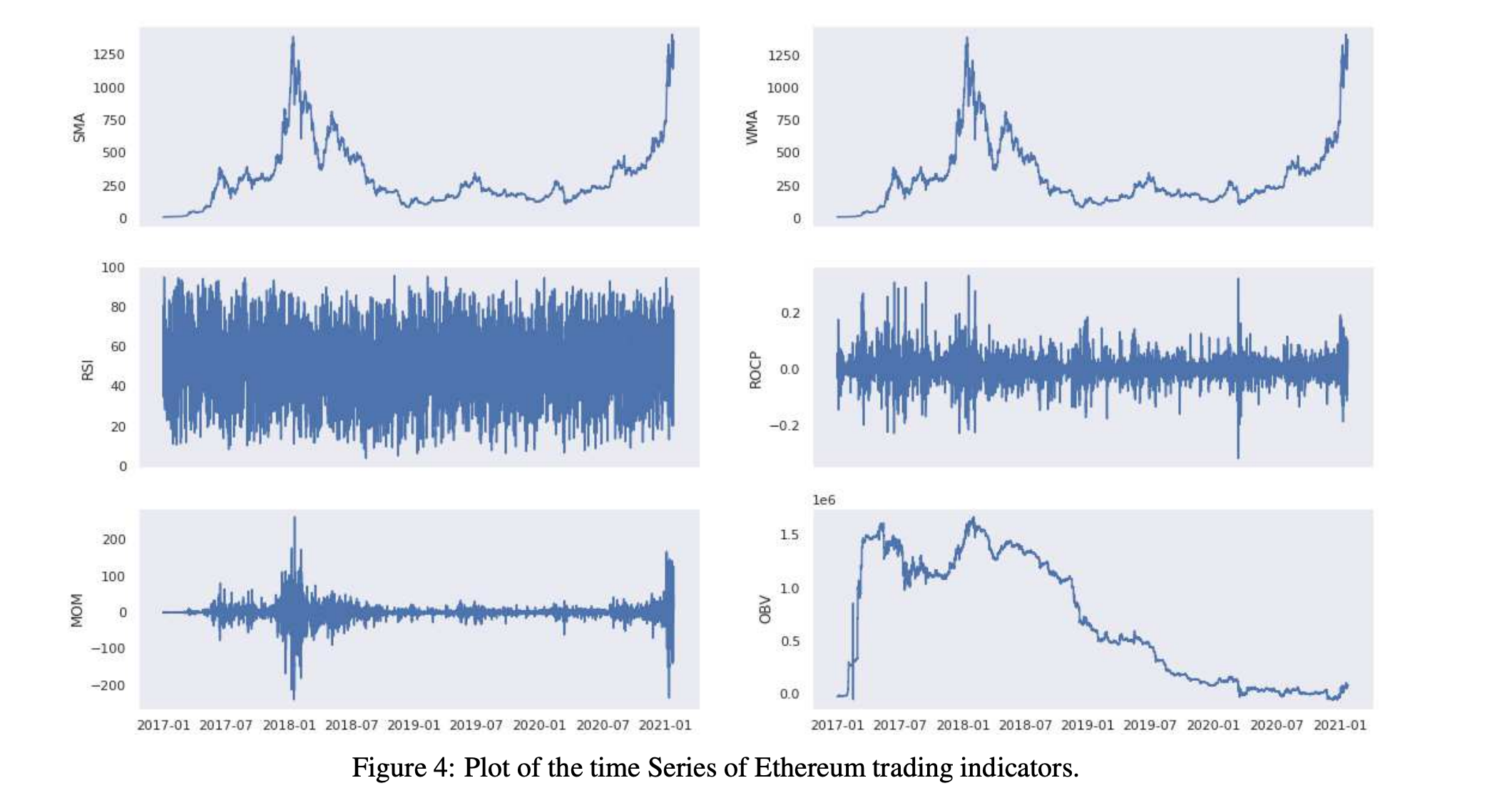
2.2 社交媒体指标 本节描述了社交媒体指标的时间序列是如何分别从以太坊和比特币开发者对Github的评论和用户对Reddit的评论构建的。特别是,对于Reddit,我们考虑了表6中列出的四个子Reddit通道。考虑的时间段为2017年1月至2021年1月。
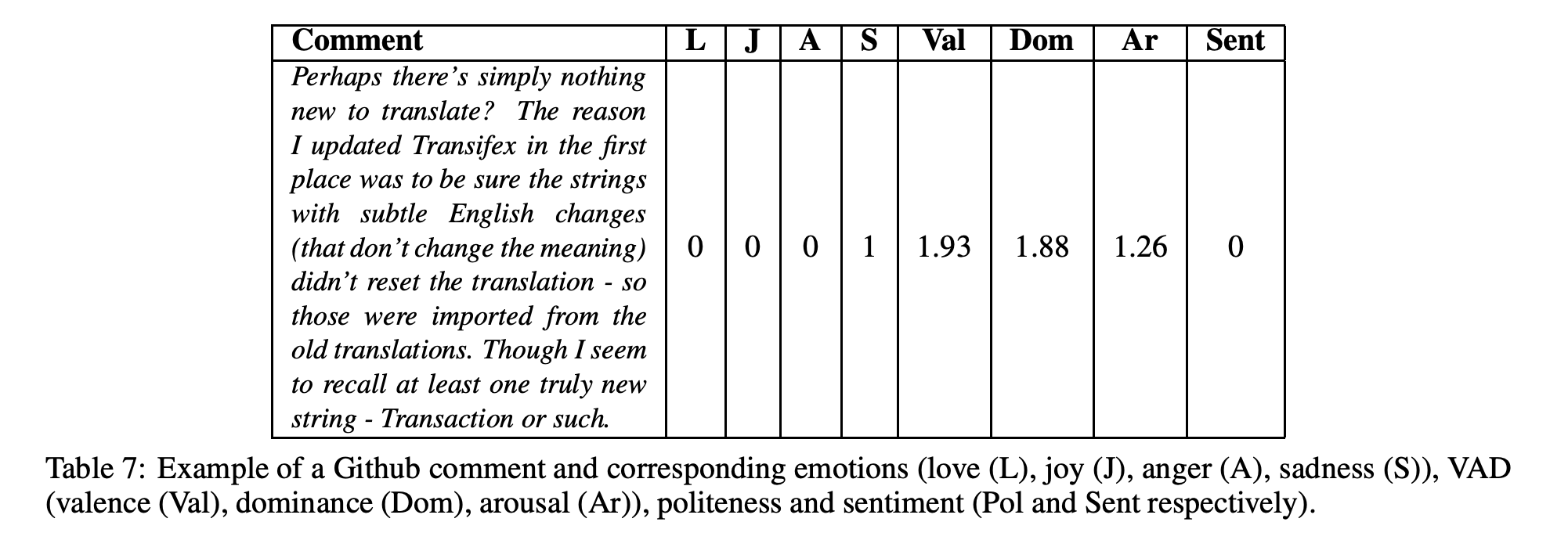
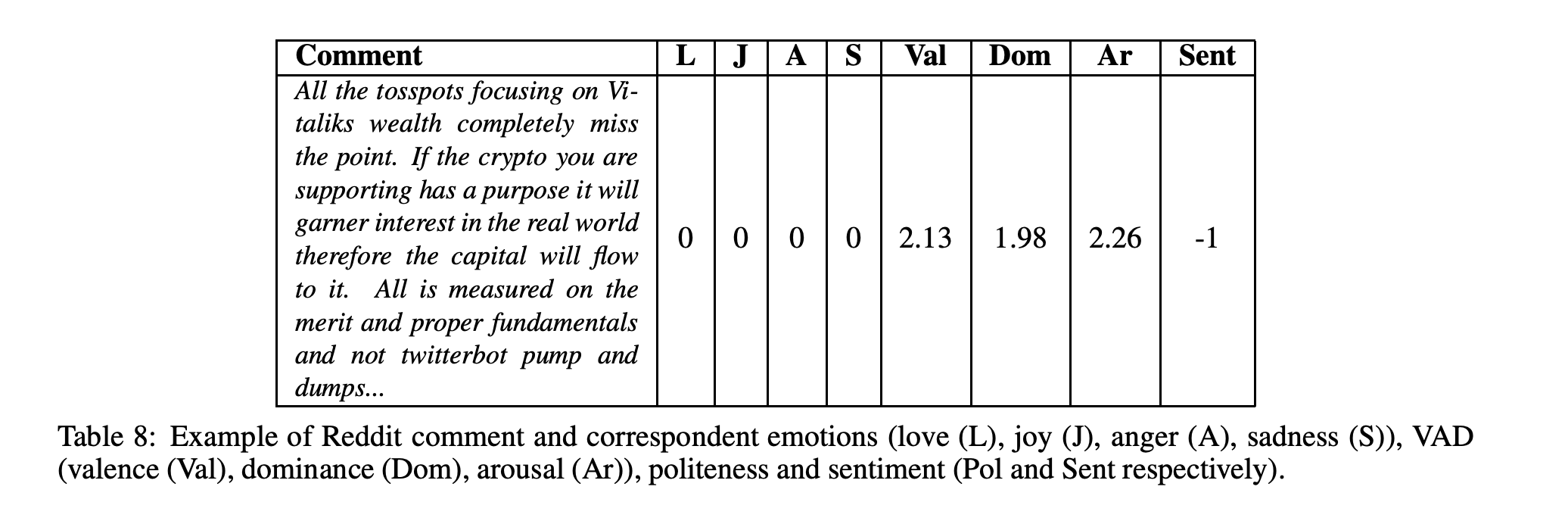
从Github for Ethereum中提取的开发人员注释和从Reddit r/Ethereum中提取的用户注释的示例可以在表7和表8中看到。如本例所述,与评论相关的情绪的定量度量是使用最先进的文本分析工具计算的(下面将进一步详述)。为每条评论计算的这些社交媒体指标是情感,如爱(L)、快乐(J)、愤怒(A)、悲伤(S)、VAD(效价(Val)、支配(Dom)、唤醒(Ar))和情感(Sent)。
2.3 通过深度学习评估社交媒体指标 我们使用深度、预训练的神经网络从BERT模型[8]中提取社交媒体指标,称为双向编码器表示。BERT和其他转换器编码器结构已经成功地运行在自然语言处理(NLP)中的各种任务,代表了自然语言处理中常用的递归神经网络(RNN)的发展。他们计算适合在深度学习模型中使用的自然语言的向量空间表示。BERT系列模型使用Transformer编码器体系结构在所有标记前后的完整上下文中处理输入文本的每个标记,因此得名:Transformers的双向编码器表示。BERT模型通常是在一个大的文本语料库上进行预训练,然后针对特定的任务进行微调。这些模型通过使用一个深度的、预先训练的神经网络为自然语言提供了密集的向量表示,较换器结构如图5所示。 转换器基于注意力机制,RNN单元将输入编码到一个隐藏向量ht,直到时间戳t。后者随后将被传递到下一个时间戳(或者在序列到序列模型的情况下被传递到转换器)。通过使用注意力机制,人们不再试图将完整的源语句编码成一个固定长度的向量。相反,在输出生成的每个步骤中,允许解码器处理源语句的不同部分。重要的是,我们让模型根据输入的句子以及到目前为止它产生了什么来学习要注意什么。 Transformer体系结构允许创建在非常大的数据集上训练的NLP模型,正如我们在这项工作中所做的那样。由于预先训练好的语言模型可以在特定的数据集上进行微调,而无需重新训练整个网络,因此在大数据集上训练这样的模型是可行的。 (责任编辑:admin) |